



Na era da pós-verdade, a mentira ganha uma roupagem especial. Em um momento histórico no qual pode se checar mais fatos do que nunca e tudo é passível de verificação, não é fácil mentir.
Mas, neste artigo, vamos descobrir através de exemplos e observações valiosas que é possível não só ser enganado com dados manipulados, mas também se enganar de maneira não intencional diante de dados sujos ou de baixa qualidade.
Não é preciso ser cientista, matemático ou conhecedor de áreas exatas para compreender que, muitas vezes, histórias bem contadas podem retirar a neutralidade dos números e fazer o mais cético acreditar em uma falácia.
Trabalhar com dados em busca de insights, direcionamentos, tendências e verdades, portanto, deve vir acompanhado de um bom pé atrás e de pessoas qualificadas, ainda mais na era do Big Data - que pode intensificar ainda mais esse problema.
Fato é que: apesar dos dados serem traiçoeiros, não há outra alternativa senão decifrá-los. Segundo uma pesquisa da New Vantage Partners deste ano, o investimento em dados e iniciativas de AI está em uma crescente: 97% das empresas respondentes estão investindo em soluções de dados e 91%, em IA. Entre elas, 92,1% relatam que estão conseguindo resultados positivos e mensuráveis em 2022, contra 48,4% em 2017 e 70,3% em 2020.
No entanto, as organizações ainda enfrentam desafios nos seus esforços para se tornarem orientadas a dados. A seguir, vamos entender como toda boa mentira contada com dados precisa ser, em grande parte, uma verdade. Parece contraditório, mas veremos que faz sentido.
Armadilhas dos dados: conheça 5 interpretações perigosas
Não se deve simplesmente aceitar uma ideia só porque ela está cercada por números. O escritor Darrell Huff, no clássico livro "Como mentir com estatística", entende os motivos dessa aceitação acrítica e revela algumas interpretações perigosas que costumam ser apresentadas sobre dados.
Aqui, vamos colocá-las em um contexto de negócios.
1. Amostra tendenciosa
Quando uma informação é obtida através de uma amostra pequena ou inapropriada, o resultado da pesquisa pode ser tendencioso.
Por exemplo, em uma empresa de varejo, uma CIO está determinada a usar modelos preditivos e inteligência artificial para entender tendências de compra e, com isso, repensar compras para o estoque, fornecedores e outras variáveis logísticas.
No entanto, ao invés de trabalhar com dados segmentados e profundos dos seus clientes, e da região onde a marca atua, ela opta por uma amostra nacional de um banco de dados comprado para definir o produto mais competitivo.
A menos que este seja um primeiro passo para uma expansão de marca, esta é uma aposta arriscada, já que a amostra nacional é aleatória e tende a não se aproximar tanto da realidade dos clientes da empresa.
Amostras tendenciosas são as mais comuns em bancos de dados comprados aleatoriamente, isso porque variáveis como renda, opinião política, escolaridade, bairro, hábitos de consumo, entre outros, podem mudar completamente o resultado.
2. A média bem escolhida
Se um estudo tem interesse em te fazer concordar ou discordar de um fato usando uma média aritmética, mediana ou modal - a escolha da média vai fazer toda a diferença.
Vamos supor que uma seguradora esteja conduzindo um levantamento sobre a renda média de um bairro para poder melhorar a precisão de suas cotações. Se um corretor não interpreta corretamente os dados, pode acabar perdendo clientes por se basear em um valor como: R$15 mil, R$3.500 ou até R$7 mil.
Todos esses podem estar corretos, mas ao não fazer uma cotação personalizada por cliente ou mesmo, por não clusterizá-los em valores de renda mais próximos, o corretor acaba sendo enganado e prejudicado pelos números.
Neste caso, R$15 mil é a média aritmética. Ou seja, a soma de todas as rendas e a divisão delas pelo número de famílias de um bairro. A mediana corresponde ao R$ 3.500, pois entende que metade das famílias ganha mais do que esse valor; e a outra metade, menos. E a média modal de R$7 mil é referente ao número encontrado com mais frequência no total das famílias.
3. Os números escondidos
Você sabia que em 80% das vezes que jogamos uma moeda para o alto, o resultado vai ser coroa? Na verdade, isso aconteceu agora que joguei 10 vezes uma moeda e, por 8 vezes, o resultado foi coroa.
Então, onde está o problema? A amostra é muito pequena e, na verdade, a probabilidade correta é de 50% de ser cara ou coroa.
Se pensarmos que um banco está utilizando um modelo preditivo fraco ao avaliar clientes para decidir se concede ou não um empréstimo, pode-se perder uma oportunidade, caso considere uma amostra muito reduzida ou desatualizada.
Ou seja, com uma amostra de dados pobre e um modelo preditivo ruim, observamos apenas que 1x vez um cliente deixou de pagar o cartão de crédito, logo, ele é um mau pagador e não consegue o empréstimo.
Com um trabalho de qualidade, podemos descobrir que, entre todas as faturas, essa dívida ocorreu em 2001, foi quitada no mesmo ano e, inclusive, que esse cliente agora tem bens de alto valor em seu nome.
4. O número semiligado
Quando não é possível provar o desejado, mostra-se outra coisa equivalente. Quando queremos muito que algo seja verdade, podemos fazer associações falsas mesmo que não intencionalmente.
Vamos imaginar que uma rede hoteleira quer fazer uma promoção para famílias se dizendo 'o hotel preferido pelas crianças'. Se o hotel se apoiar em um levantamento do sindicato regional, que constatou que aquele foi o estabelecimento que recebeu mais crianças em 1 ano, e não observar nenhum dado de pesquisa própria ou NPS via Wi-Fi, pode acabar não vendo a associação errada que fez e prejudicar sua reputação.
Isso porque ter recebido mais crianças quantitativamente não significa que o hotel tenha áreas e quartos pensados para evitar acidentes, possua brinquedos e recreações ou, de fato, opiniões de clientes favoráveis a esse slogan.
No entanto, essa pode ser uma oportunidade para entender um nicho de mercado que melhor atende, e investir em melhorias focadas em novos rumos de negócio.
5. Correlação coincidente
Esta é uma das falácias mais antigas! Mas tem grande chance de aparecer em materiais estatísticos e envolvendo dados. Basicamente, ela ocorre quando dizem que se B aconteceu depois de A, então A causou B. Ou seja, é uma relação falsa de causa e efeito.
Por exemplo, uma rede de academias percebe um decréscimo na quantidade de matrículas e saída gradual de muitos alunos, em um período curto de tempo, e relaciona isso ao fim do verão. Usar esse fato sazonal como justificativa é a alternativa mais fácil e óbvia.
No entanto, dados cruzados poderiam mostrar que aquela região da cidade começou a ter um aumento muito grande de moradores jovens, e que a nova grade de horários das aulas não correspondia ao perfil deles.
O que fazer quando dados são o problema?
Mesmo dados brutos, antes de qualquer higienização ou tratamento, antes de gerarem insights, também contêm mentiras. E com dados mal estruturados e sujos, por melhor que seja a análise, ela chegará a uma conclusão falsa.
E essa condição é o que torna verdades evidentes e tendências óbvias em confusos e contraditórios caminhos de investimento. Quando dados sujos e de baixa qualidade são um problema, normalmente a origem está nos seguintes processos.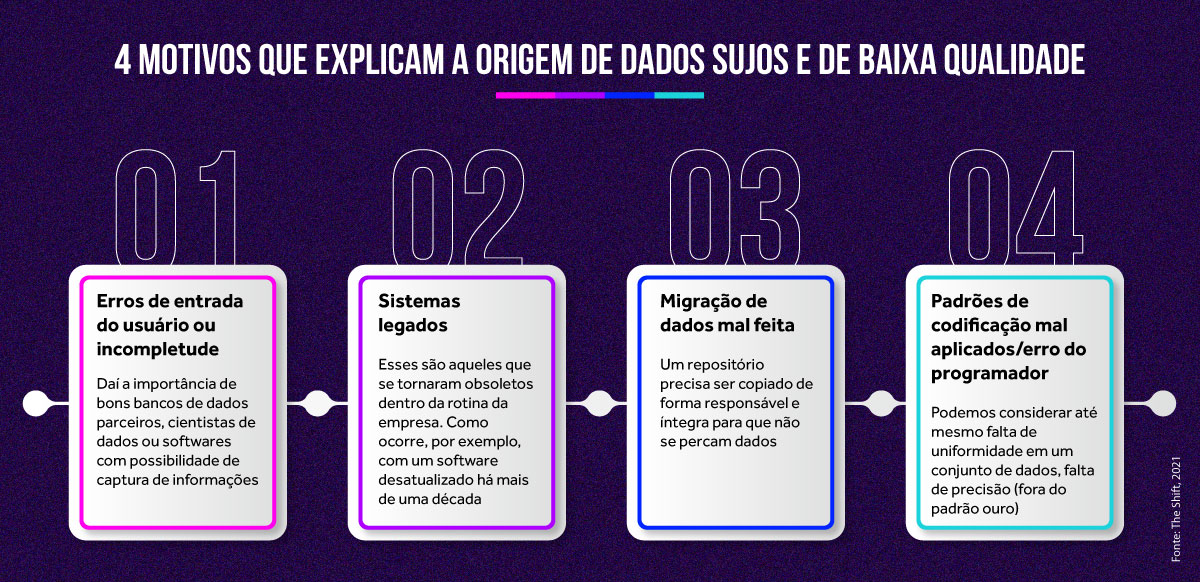 E para não cometer esses erros e, com isso, obter uma boa análise de dados, a sua matéria prima deve ser bem cuidada para não guiar a sua empresa para armadilhas e também permitir uma interpretação precisa e correta da realidade.
E para não cometer esses erros e, com isso, obter uma boa análise de dados, a sua matéria prima deve ser bem cuidada para não guiar a sua empresa para armadilhas e também permitir uma interpretação precisa e correta da realidade.
Para higienizar e tratar dados, há algumas metodologias inteligentes e bem úteis, na opinião do Evangelista de Big Data da IBM, James Kobielus. Entre elas,
- Aprendizagem por conjunto: ela é útil para descobrir se modelos distintos convergem em um mesmo padrão estatístico. Ou seja, se eles, que usam um mesmo grupo de dados, mas com amostras e algoritmos diferentes, chegam a resultados que fazem sentido.
- Teste A/B: é quando 2 modelos são utilizados ao mesmo tempo com variáveis diferentes, mas em uma mesma constante. Quando chegam os resultados, conseguimos dizer qual modelo é mais preciso com relação à variável de maior interesse.
- Modelagem robusta: se as previsões feitas são estáveis e trabalham com bases de dados parceiras para complementação, elas fazem parte de uma modelagem robusta - o perigo dessa abordagem é acabar escondendo ainda mais padrões ou acabar surpreendendo com novos modelos.
E como não cair em mentiras com dados?
Apesar de saber que o ideal é realmente se alfabetizar em dados - saber fazer uma boa leitura, interpretação e tomada de decisão a partir deles - não é preciso ser cientista para aprender a desconfiar de dados manipulados, insights enganosos ou informações pobres.
No livro de Huff, ele elenca 5 perguntas para fazer antes de pensar em confiar em informações obtidas com dados.
- Quem diz isto?
- Como essa pessoa sabe disto?
- O que está faltando?
- Alguém mudou de assunto?
- Isto faz sentido?
Na 1ª pergunta, o autor encoraja a investigação com relação à origem da informação. Na 2ª, o questionamento é acerca dos métodos utilizados, a amostra observada. Na 3ª pergunta, o ponto central é a interpretação dos resultados, se é parcial ou não.
Já na 4ª pergunta pretende entender os interesses envolvidos. Ou seja, se quem fez a pesquisa poderia desejar obter um resultado específico. E por fim, em “Isto faz sentido?”, a provocação recai em cima da legitimidade do resultado.
Resumindo, é preciso fazer perguntas incômodas para evitar que falácias levem gestores ou mesmo uma empresa inteira ao fracasso. A união deve ser entre investimentos em tecnologia de ponta, softwares qualificados e bases de dados robustas, e bons times de análise e negócios.
Quer saber mais?
Para aprofundar seus conhecimentos sobre modelos preditivos, aprendizagem de máquina e inteligência artificial, baixe nosso eBook gratuito sobre Análise de Sentimento, um dos recursos mais recentes e poderosos para identificar dados comportamentais.

.png)


{kind=link}
Comentários