


We live in the age of data. That's no news. According to a study by the author and corporate consultant specialized in big data and business performance, Bernanrd Marr, published by Forbes, every second we create a new piece of data. On Google alone, humanity runs about 40,000 queries/second, or 3.5 billion searches per day and 1.2 trillion per year.
When we face this volume of information, whether to conduct a study, illustrate a theory, or present results or trends at work, we are faced with a great complexity in filtering this data and obtaining answers from it.
This is why, due to the need for agile and accurate answers and to accelerate the digital transformation to become data-driven, many companies and professionals seek to build data pipelines.
- Get to know more: How to boost your business with data?
- Read also: How to not fall for lies using data?
This term has become a favorite of the big data market because it has a major impact on businesses in various industries. In this article, we will understand what a data pipeline is, its basic parts and processes, its relationship with data lake and data warehouse, and its role in generating valuable insights.
To recap: what is big data?
This term is used to name both an area of knowledge and simply to define a large volume of data, structured or unstructured, generated and stored in large quantities, and requiring specific treatments, innovative technologies, such as clusters, parallel processing, distributed computing, among others.
As an example, this data can be market analysis, competition, social networks, access data, customer records, financial transactions, descriptions of internal business processes, among others. The difference lies in the fact that traditional or manual systems are not able to handle this volume to organize it and extract insights.
The people responsible for this work are Information Technology (IT) professionals - such as Scientists, Engineers, Data Architects, BI Analysts - who specialize in these systems, and have advanced knowledge in statistics and information processing. They can analytically answer key business questions through mountains of data, identifying patterns and predicting trends.
And how does the Data Pipeline work in this context?
A data pipeline is intended to function like a tunnel, a connector. It moves data from one place to another following a series of processes from the source to the destination of interest, which can be a data lake or a data warehouse, for example.
In functional terms, therefore, a data pipeline consists of 3 elements:
- a source
- one or more processing steps
- and a target
It is in the second stage, the processing stage, that the raw and unstructured data are transformed into treasures, valuable insights, strategic and - the best - intelligible and simpler to be analyzed by teams of innovation, marketing, Customer Success, finance, sales, performance, and many others.
This flow should be part of every company that wants to become data-driven, and should be understood and valued by leadership professionals who want a sustainable future for the businesses in which they operate.
Setting up the architecture of a data pipeline is a very complex task depending on the goal of the pipe, the market niche it serves, and the types of filters needed. In addition, of course, to the errors that can happen in the processing steps - the source can have multiple identical copies, data can be corrupted, and more.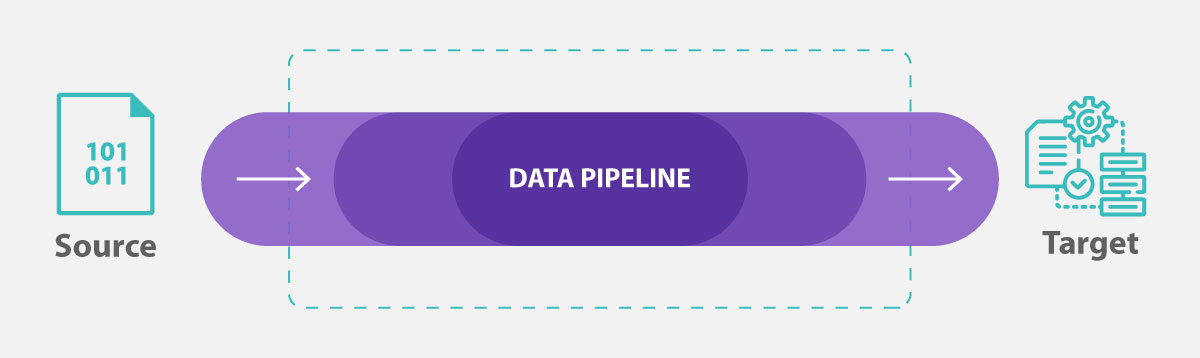 About these steps, they are:
About these steps, they are:
Origin
Any type of data can serve as an origin: personal, legal, demographic, behavioral and other databases. Most data pipelines originate data from multiple sources that help the pipeline build an even more reliable data validation, verification, and cleansing process.
Transformation
After capture, the data is modified, changed according to a pattern, order, and also sanitized, i.e. duplicates are deleted, data is confirmed and verified. So the data is cleaned.
Dataflow
In this step, the data moves from the source to its destination. It consists of the movement of data from source to destination, with information processing and transformations from the data silos they pass through.
Processing
Related to Dataflow, but variable according to the volume of big data and the latency of the data. That is, the speed with which it passes and is processed by the data pipeline.
Destino
The data is usually stored in a data warehouse, data lake, or even in an analytics application.
How does it relate to data lake and data warehouse?
First of all, data lake and data warehouse are data repositories with high levels of security. A company can choose which one makes more sense for its business, or have both, taking into consideration the processes it addresses, and the purpose of the data pipeline.
A data lake can be defined as a warehouse for large structured, unstructured, and semi-structured data that allows you to explore a given piece of data whenever you want without having to move it to a system, or even to share analysis and insights about that data with users on the same team.
Although data lakes allow you to access all kinds of data in one place, and this makes it easier to correlate everything for analysis and insights, data lakes are not systems, and most of the time data is moved to systems like Redshift or a Dashboard Tool, among others.
A data lake is therefore a storage strategy tool, since data can be stored in many different ways and come from many different sources. The relevance of having a data lake grows the more a company has unstructured data, since a data lake allows, in an organized way, that different areas of the same company use this information in a democratic way.In contrast, a data warehouse concentrates big data from various sources and with a robust history of changes and origins. This can be very useful for analytics teams, because then it is possible to work with the data in various ways, without losing the history of these analyses and changes.
A natural path after data has been analyzed and processed in a data lake is for it to be moved to a data warehouse and, now structured, to be worked on and generate insights for a company.
- Leia também: Data Lake and Data Warehouse: What is the difference and which one is best for your business?
And how does this help create data-driven insights?
With this huge volume of data being worked on by your company or even being organized by an outsourced partner company, your business can find real treasures that are fundamental to its survival and to sharpening the competition.
As the entire path of a data pipeline helps make the data intelligible, usable by various teams, it becomes easier to obtain information that demystifies the target consumer's behavior, initiate automation processes, purchase journeys, more segmented projects focused on customer experience, invest in business intelligence, anticipating trends and accelerating successful, more strategic decision-making, among other advantages.
In addition, structured data optimizes the work of your teams in obtaining insights and helps them manage their time better, since the data can help them make much more accurate decisions according to the company's context, the market moment, etc.
Moreover, data pipelines are also excellent for information security. Secure data is fundamental not only for a company to protect itself against privacy and data protection legislation, but is even a way to prevent that, indiscriminately, anyone inside or outside the company has access to sensitive information. These tools have distinct silos of data that allow or block access depending on the user's permission.
Viewed from a financial perspective, a data pipeline also adds value. This is because it is possible to reverse losses and turn them into not only capital gains, but also operational gains.
Let's look into a hypothetical example from the retail industry.
A large clothing company collects data internally, from customers and partners, and has all of them available, in an unstructured way, in e-commerce channels and systems, physical points, and digital marketing.
Facing a considerable slowdown in revenues for a few months, the brand decides to hire a company specialized in data intelligence to build a data pipeline and identify the problems.
With all the data from various sources and understanding the brand's business goals, the data scientists, engineers, and architects, IT and project managers start working on structuring, transforming, sanitizing the data, the dataflow pipeline, and all the processes we mentioned above.
The Pipeline built delivered incredible insights to the decision makers of the clothing brand that helped save the company from further losses and even recover what it had lost in the last months.
A sales fluctuation was noticed in specific points of certain physical stores that were not hitting sales targets due to being poorly located and with products that were poorly targeted to the local audience.
The company's Marketing team was able to reposition the brand based on the data obtained, failures in digital customer service were identified, cart abandonment due to lack of follow-up, and a recurring problem in the payment software.
All this feedback was essential to:
- develop a training program for the online and physical sales team
- closing and opening physical stores in a more strategic way with stock oriented to local customers
- improve the performance of marketing campaigns through segmentation
In other words, with big data structured into data pipelines of quality, added to the business insight of executives and analysis by IT professionals, there is no company that will not take off towards success and get ahead of the competition.
Want to learn more? Download our free ebook
If you want to learn more about the power of data for business, download our free eBook on Sentiment Analysis, one of the latest and most powerful resources for identifying behavioral data.



{kind=link}
Comments