


Vivemos na era dos dados, por isso o pipeline de dados é tão importante. Segundo um estudo do escritor e consultor corporativo especializado em big data e desempenho empresarial, Bernanrd Marr, publicado na Forbes, a cada segundo, criamos um novo dado. Só no Google, a humanidade realiza cerca de 40.000 consultas/segundo, ou seja, 3,5 bilhões de buscas por dia e 1,2 trilhão por ano.
Quando encaramos esse volume de informação, seja para fazer um estudo, ilustrar uma teoria, ou apresentar resultados ou tendências no trabalho, nos deparamos com uma complexidade grande na filtragem desses dados e na obtenção de respostas a partir deles.
Por isso, pela necessidade de respostas ágeis e precisas e de acelerar a transformação digital para se tornar data-driven, que muitas empresas e profissionais buscam construir data pipelines, ou pipelines de dados.
- Saiba mais: Como alavancar seu negócio com dados?
- Leia também: Como não cair em mentiras com dados?
E esse termo já virou um queridinho do mercado de big data porque gera um grande impacto em negócios dos mais variados ramos. Neste artigo, vamos entender o que é um pipeline de dados, suas partes e processos básicos, sua relação com data lake e data warehouse e sua função na geração de insights valiosos.
Recapitulando: o que é big data?
Em uma tradução literal, Big Data são "Grandes Dados". Esse termo é utilizado para nomear tanto uma área do conhecimento quanto para simplesmente definir um volume grande de dados, estruturados ou não, gerados e armazenados em grande quantidade, e que requerem tratamentos específicos, tecnologias inovadoras, como os Clusters, processamento paralelo, computação distribuída, entre outras.
Exemplificando, esses dados podem ser análises de mercado, concorrência, redes sociais, dados de acesso, cadastros de clientes, transações financeiras, descrições de processos empresariais internos, entre outros. A diferença está no fato de que sistemas tradicionais ou manuais não são capazes de lidar com esse volume para organizá-los e conseguir extrair insights.
Assim fazem os profissionais de Tecnologia da Informação (TI) - como Cientistas, Engenheiros, Arquitetos de Dados, Analistas de BI - que são especializados nesses sistemas, e têm conhecimentos avançados em estatística e processamento de informações. Eles conseguem, de forma analítica, responder perguntas chave para negócios através de montanhas de dados, identificando padrões e antevendo tendências.
- Saiba mais: Big Data: 6 Vantagens para a Sua Empresa
E como funciona o Pipeline de Dados nesse contexto?
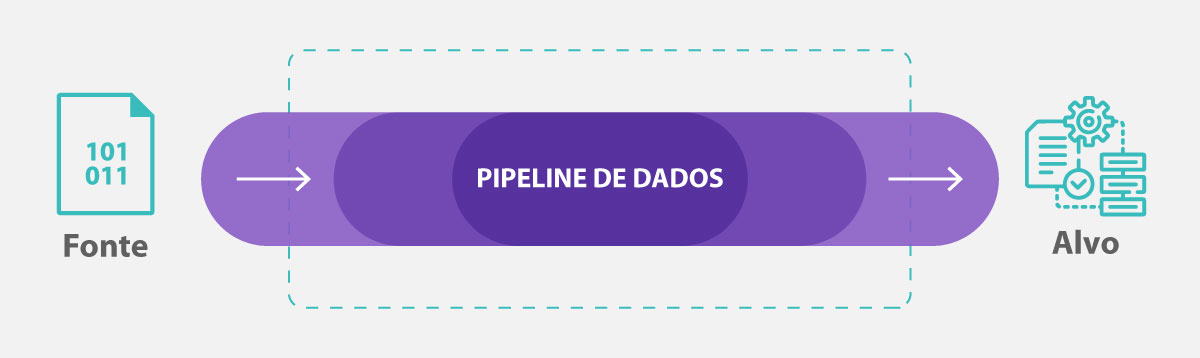
Um pipeline de dados tem o objetivo de funcionar como um túnel, um conector. Ele move dados de um lugar para outro seguindo uma série de processos da fonte até o destino de interesse, que pode ser um data lake ou uma data warehouse, por exemplo.
Em termos funcionais, portanto, um pipelines de dados consiste em 3 elementos:
- uma fonte
- uma ou mais etapas de processamento
- e um destino
É na segunda etapa, a do processamento, que os dados brutos e desestruturados se transformam em tesouros, insights valiosos, estratégicos e - o melhor - inteligíveis e mais simples para serem analisados por equipes de inovação, marketing, Customer Success, finanças, vendas, performance e muitas outras.
Esse fluxo deve fazer parte de toda empresa que quer se tornar data-driven e deve ser compreendido e valorizado pelos profissionais de liderança que querem um futuro sustentável para os negócios em que atuam.
- Leia também: Como dados vão permitir melhores experiências a clientes e transformar o futuro do varejo
Montar a arquitetura de um pipeline de dados é uma tarefa bem complexa a depender do objetivo do pipe, do nicho de mercado que atende e dos tipos de filtros necessários. Além, é claro, dos erros que podem acontecer nas etapas de processamento - a fonte pode ter várias cópias idênticas, dados podem ser corrompidos e muito mais. Sobre essas etapas, elas são:
Sobre essas etapas, elas são:
Origem
Todo tipo de dado pode servir como origem: bases de dados pessoais, jurídicos, demográficos, comportamentais e outros. A maioria dos pipelines de dados tem como origem dados de múltiplas fontes que ajudam o pipeline a construir um processo de validação, verificação e limpeza dos dados ainda mais confiável.
Transformação
Depois da captura, os dados são modificados, alterados de acordo com um padrão, ordem, e também higienizados, ou seja, duplicatas são excluídas, dados são confirmados e verificados. Assim, os dados ficam limpos.
Dataflow
Nesta etapa, os dados se movimentam da origem até o seu destino. Consiste no movimento dos dados da origem até o destino, com o processamento das informações e transformações a partir dos silos de dados por onde passam.
Processamento
Relacionado ao Dataflow, mas variável de acordo com o volume de big data e a latência dos dados, ou seja, a velocidade com a qual eles passam e são processados pelo pipeline de dados.
Destino
Os dados costumam ser armazenados em um Data Warehouse, Data Lake, ou mesmo em uma aplicação de analytics.
Qual a relação dele com data lake e data warehouse?
Primeiramente, data lake e data warehouse são repositórios de dados com altos níveis de segurança. Uma empresa pode optar entre qual desses faz mais sentido para o seu negócio, ou ter os dois, levando em consideração os processos que aborda, e a finalidade do data pipeline.
Um data lake pode ser definido como um armazém para grandes dados estruturados, não estruturados e semiestruturados, que permite que você explore um determinado dado sempre que quiser sem precisar movê-lo para um sistema, ou mesmo para compartilhar análises e insights sobre esses dados com usuários de uma mesma equipe.
Apesar de data lakes permitirem o acesso a dados de todo tipo em um único local, e isso facilitar correlacionar tudo para obter análises e insights, data lakes não são sistemas e, na maioria das vezes, os dados são movidos para sistemas como o Redshift ou então uma Ferramenta de Dashboard, entre outros.
Um data lake é, portanto, uma ferramenta de estratégia de armazenamento, já que os dados podem estar armazenados de diversas formas e vir de diversas fontes. A relevância de ter um data lake cresce quanto mais uma empresa tiver dados desestruturados, já que um data lake permite, de forma organizada, que áreas diferentes de uma mesma empresa usem essas informações de forma democrática.
Já um data warehouse concentra grandes dados de várias fontes e com todo um histórico robusto de alterações e origens. Isso pode ser muito útil para times de analytics, porque assim é possível trabalhar com os dados de várias formas, sem perder o histórico dessas análises e alterações.
Um caminho natural após a análise e processamento de dados em um data lake, é que eles passem para um data warehouse e possam, agora estruturados, serem trabalhados e gerarem insights para uma empresa.
E como isso ajuda a criar insights data-driven?
Com esse enorme volume de dados sendo trabalhado pela sua empresa ou mesmo sendo organizado por uma empresa parceira de forma terceirizada, o seu negócio pode encontrar verdadeiros tesouros fundamentais para a sobrevivência dele e para acirrar a competição a concorrência.
Como todo o caminho de um pipeline de dados ajuda a tornar os dados inteligíveis, utilizáveis por equipes diversas, torna-se mais fácil obter informações que desmistifiquem o comportamento do consumidor alvo, dar início a processos de automação, jornadas de compra, projetos mais segmentados focados na experiência do cliente, investir na inteligência de negócios, antecipando tendências e acelerando tomadas de decisão de sucesso, mais estratégicas, entre outras vantagens.
Além disso, dados estruturados otimizam o trabalho das suas equipes na obtenção de insights e ajudam a gerenciar melhor o tempo delas, já que os dados podem ajudá-las a tomar decisões muitos mais certeiras de acordo com o contexto da empresa, o momento do mercado etc.
No mais, pipelines de dados também são excelentes para a segurança da informação. Dados seguros são fundamentais não só para que uma empresa se resguarde perante legislações de privacidade e proteção de dados, mas são formas até de evitar que, de forma indiscriminada, qualquer pessoa dentro ou fora da empresa tenha acesso a informações sensíveis. Essas ferramentas possuem silos distintos de dados que permitem ou bloqueiam o acesso dependendo da permissão do usuário.
Observado por um prisma financeiro, um pipeline de dados também agrega valor. Isso porque é possível reverter perdas e transformá-las em ganhos não só de capital, como também operacionais.
Vamos a um exemplo hipotético na indústria do varejo.
Uma grande empresa de roupas coleta dados internos, de clientes e parceiros e tem todos eles disponíveis, de forma desestruturada, em canais e sistemas de e-commerce, pontos físicos e marketing digital.
Diante de uma desaceleração considerável no faturamento por alguns meses, a marca decide contratar uma empresa especializada em inteligência de dados para construir um pipeline de dados e identificar os problemas.
Com todos os dados das diversas origens e entendidos os objetivos de negócio da marca, os cientistas, engenheiros, e arquitetos de dados, gerentes de TI e e projetos começam a trabalhar na estruturação, transformação, higienização dos dados, no dataflow do pipeline, e em todos os processos que citamos acima.
O Pipeline construído entregou aos tomadores de decisão da marca de roupas insights incríveis que ajudaram a salvar a empresa de perdas maiores e ainda a recuperar o que perdeu nos últimos meses. Foi percebida uma oscilação de vendas em pontos específicos de determinadas lojas físicas que não estavam batendo metas de vendas por estarem mal localizadas e com produtos pouco focados para o público local.
A equipe de Marketing da empresa pode reposicionar a marca partir dos dados obtidos, foram identificadas falhas no atendimento digital, abandono de carrinho por falta de follow-up e um problema recorrente no software de pagamentos.
Todos esses feedbacks foram essenciais para:
- elaborar um treinamento para a equipe de vendas online e nos pontos físicos
- fechar e abrir lojas físicas de forma mais estratégica com estoque orientado aos clientes locais
- melhorar a performance de campanhas do marketing por meio de segmentação
Ou seja, com big data estruturado em pipelines de dados de qualidade, somados ao olhar de negócios de executivos e análises de profissionais de TI, não há empresa que não decole rumo ao sucesso e consiga se antecipar à concorrência.
Quer saber mais? Baixe nosso ebook gratuito
Se você quer saber mais sobre o poder dos dados para negócios, baixe nosso eBook gratuito sobre Análise de Sentimento, um dos recursos mais recentes e poderosos para identificar dados comportamentais.




{kind=link}
Comentários